
History of AI Video Generation: The Full AI Video Timeline From GANs to Sora
The history of AI video generation is not just an academic timeline; it’s the battle-tested origin story of the tools that Marketers, Creators, and Freelancers now rely on to survive intense performance pressure. From the controversial emergence of Deepfakes to the cinematic power of Sora, each milestone represents a solution to a real-world production problem. Within the world of AI Video Generation, understanding this evolution from foundational models like GANs to the more robust Diffusion Models is crucial to mastering the modern toolkit. This expert guide unpacks the key technological leaps that took us from flickering, unstable clips to high-fidelity, narrative-driven content. We will explore a visual timeline of key milestones, unpack the spark of creation with GANs and Deepfakes, detail the leap to realism with Diffusion Models, chart the cinematic revolution led by Sora and Pika, and connect these breakthroughs to the features in your toolkit today by highlighting the foundational research papers that made it all possible.
Table of Contents
A Visual Timeline: Key Milestones in AI Video Generation
To grasp the rapid evolution of AI video, it’s best to visualize the journey. The technology has progressed through distinct eras, each building upon the last to deliver the powerful tools creators use today. This timeline summarizes the pivotal moments that transformed AI video from a research concept into a practical solution for content production.
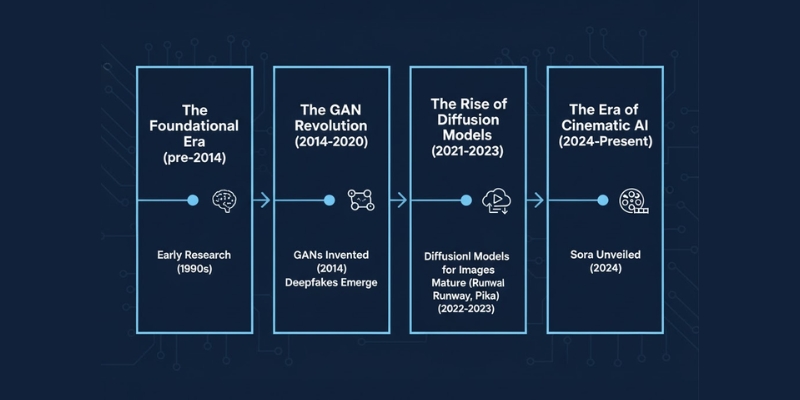
The Foundational Era (pre-2014): While modern AI video feels new, its roots trace back to academic experiments in the 1990s, such as the Video Rewrite program in 1997, which used machine learning to alter a speaker’s mouth movements in a video to match a new audio track. These early projects were foundational but lacked the realism and scalability needed for practical use.
The GAN Revolution (2014-2020): The true starting point for the modern era was 2014 with the invention of Generative Adversarial Networks (GANs). This breakthrough provided the first viable framework for generating realistic synthetic media. This era was defined by the public’s first encounter with AI-generated video through the controversial rise of Deepfakes around 2017, which used GANs for face-swapping.
The Rise of Diffusion Models (2021-2023): The next major leap came with the refinement of Diffusion Models. These models proved to be superior to GANs in producing high-fidelity, coherent, and temporally consistent images and videos. This technological shift was the catalyst for the development of commercially viable tools like Runway and Pika, which brought advanced AI video features to the mainstream.
The Era of Cinematic AI (2024-Present): The launch of models like OpenAI’s Sora in early 2024 marked a new paradigm. These tools demonstrated the ability to generate longer, high-definition videos (up to a minute) that understood narrative prompts and simulated real-world physics, moving AI video from short clips to a potential tool for cinematic storytelling.
The Spark of Creation: How GANs and Deepfakes Started It All
The modern AI video revolution began with a single, powerful idea: Generative Adversarial Networks (GANs). Invented by researcher *Ian Goodfellow* in 2014, a GAN is a clever system where two neural networks are pitted against each other in a constant competition. For a Marketer or Creator, the concept is simple: one network, the “Generator,” is like an apprentice artist trying to create a realistic image (or video frame). The second network, the “Discriminator,” is like a seasoned art critic trying to spot if the artwork is a forgery. The generator keeps trying to fool the discriminator, and in doing so, it gets progressively better at creating incredibly realistic outputs.
Before GANs, generating novel, photorealistic media from scratch was largely theoretical. GANs were the first technology to truly unlock this capability, laying the groundwork for everything that would follow. They were the engine that powered the first wave of AI-generated media.
The first widely known—and highly controversial—application of GANs for video was the emergence of Deepfakes around 2017. The term was coined on Reddit, where users employed open-source face-swapping technology to place celebrities’ faces into existing videos. While the initial use cases were often unethical, Deepfakes served as a crucial proof of concept. For the first time, the general public witnessed the power of AI to synthesize and manipulate video content convincingly. This moment, though fraught with ethical concerns which you can explore in our guide to the ethics of AI video, was the catalyst that set the stage for more productive and creative applications, making it clear that AI video was no longer science fiction.
The Leap to Realism: Why Diffusion Models Were a Game-Changer
While GANs kicked off the revolution, early GAN-based video generation had significant limitations that were major roadblocks for professional use by Marketers and Creators. Videos often suffered from a flickering effect, known as temporal incoherence, where details would shift or change unnaturally between frames. They also struggled with fine detail and maintaining consistency over longer clips, making them unsuitable for any “battle-tested” marketing campaign or creative project.
The next evolutionary step that solved these problems was the rise of Diffusion Models. The core concept behind a diffusion model is both elegant and powerful. It works by taking a clear image, systematically adding “noise” (random visual static) until it’s completely unrecognizable, and then training the AI to meticulously reverse that process. By learning to denoise the image step-by-step, the model becomes incredibly adept at creating highly detailed and coherent imagery from pure noise, guided by a text prompt.
This technological shift was a true game-changer. For a detailed explanation of the mechanics, see our article on how AI video generators work. Diffusion models produce significantly higher-quality, more stable, and more realistic video outputs than their GAN predecessors. They excel at maintaining temporal consistency, meaning objects and environments stay stable from one frame to the next, eliminating the distracting flicker of early AI videos. Key academic models like Latent Video Diffusion Models (LVDM) and architectures like the Video Diffusion Transformer (VDT) pushed the technology forward, proving that diffusion was the path to achieving the photorealism required for professional applications.
From Tech Demos to Blockbusters: Sora, Pika, and the Cinematic Revolution
The recent, explosive growth in AI video is where historical evolution meets practical application for Marketers, Creators, and Freelancers. This new era is defined by tools that moved beyond short, glitchy clips to produce stunning, narratively coherent video content. The landmark moment was the unveiling of OpenAI’s Sora in February 2024. Sora demonstrated an unprecedented ability to generate up to a minute of high-fidelity 1080p video from a simple text prompt. More importantly, it showed a grasp of real-world physics and the ability to maintain character and environmental consistency, directly addressing the “from deepfakes to Sora” journey many users are curious about.
While Sora captured headlines, other key players like Pika and Runway democratized these advanced capabilities, making them accessible to mainstream creators. These platforms offered intuitive interfaces that allowed Freelancers and marketing teams to generate high-quality B-roll, animate static images, and produce entire video clips without specialized skills. This directly addresses the industry’s immense “performance pressure” on creators to produce more video content faster and cheaper. For a full breakdown, our comparison of AI video vs. traditional video production offers deep ROI insights.
This cinematic revolution connects directly to tangible outcomes for the target audience. The ability to create promotional videos, educational content, and engaging social media clips without large teams, expensive equipment, or lengthy post-production cycles is a massive competitive advantage. These tools are the direct solution for automating repetitive tasks and maximizing ROI in a video-first world.
How Historical Breakthroughs Power Your AI Video Toolkit Today
The history of AI video is not just a timeline of academic papers; it’s the direct foundation for the features that Marketers, Creators, and Freelancers use every day. Each technological leap powers a specific capability in modern AI video generators, turning abstract research into practical, ROI-driven solutions. Understanding what AI video generation is requires knowing these pillars.
GANs’ Legacy: The Rise of AI Avatars
The core technology pioneered by Generative Adversarial Networks (GANs) is the bedrock for the realistic digital avatars found in leading tools like Synthesia and HeyGen. The generator-discriminator competition was perfect for learning and replicating human faces with high fidelity. This addresses a key pain point for creators: the need to produce scalable, repeatable training or marketing videos without constantly being on camera. The ability of GANs to synthesize photorealistic faces is directly responsible for the AI avatar industry.
Diffusion Models’ Impact: Text-to-Video & Content Repurposing
The superior quality and temporal stability of Diffusion Models power the core “text-to-video” functionality that is transforming content strategy. When a marketer turns a blog post into a video or a creator visualizes a script, it’s the diffusion model’s ability to denoise random static into a coherent sequence that makes it possible. This technology enables the rapid content repurposing that is essential for modern, multi-platform marketing efforts.
Transformers and NLP: The Power of the Prompt
The final piece of the puzzle is understanding the prompt itself. Advancements in Natural Language Processing (NLP), specifically the Transformer architecture (the “T” in GPT), allow AI video tools to comprehend complex, nuanced text prompts. When a user requests “a golden retriever running through a field of flowers during golden hour in a cinematic style,” the transformer architecture deconstructs that sentence into meaningful components the diffusion model can execute. This gives creators the precise creative control needed to achieve their vision, turning natural language into a powerful directorial tool.
The Research That Paved the Way: 5 Foundational Papers
For those who want an expert deep dive, understanding the seminal research papers is key to building authority and trust. These academic milestones are the direct source code for the AI video tools we use today. Here are five papers whose impact is still felt in every AI-generated video.
“Generative Adversarial Networks” (Ian Goodfellow, et al., 2014):
This is the paper that started it all. It introduced the revolutionary generator-vs-discriminator framework, providing the first viable method for creating realistic, novel synthetic media and kicking off the modern era of generative AI.
“Denoising Diffusion Probabilistic Models” (Jonathan Ho, et al., 2020):
While the theory of diffusion existed earlier, this paper was a critical milestone that demonstrated the power of diffusion models for high-quality image synthesis, popularizing the approach and showing it could surpass GANs in fidelity, which directly paved the way for its application in video.
“Make-A-Video: Text-to-Video Generation without Text-Video Data” (Uriel Singer, et al., 2022):
This paper from Meta AI was a significant step in text-to-video generation. It demonstrated how a model could learn video dynamics from unlabeled video footage, decoupling the need for massive, paired text-video datasets and accelerating the development of text-to-video tools.
“Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding” (Chitwan Saharia, et al., for Google’s Imagen):
Although focused on images, the principles in this paper were foundational for high-quality video. It showcased the importance of using powerful, pre-trained large language models to deeply understand text prompts, leading to an unprecedented level of photorealism and prompt fidelity that later video models like Sora would build upon.
Frequently Asked Questions about the History of AI Video
When did AI video generation officially start?
While academic experiments in video manipulation have roots going back to the 1990s, the modern era of AI video generation began in 2014 with the invention of Generative Adversarial Networks (GANs). This provided the first robust framework for creating new, realistic synthetic media from data.
What is the difference between GANs and Diffusion Models for video?
GANs use a competing generator and discriminator to create media; they are often faster but can be unstable, leading to visual artifacts. Diffusion models work by systematically removing noise to construct a video, a process that generally produces higher-fidelity, more realistic, and temporally consistent results, making them the foundation for cutting-edge tools like Sora and influencing the future of AI video.
Was Deepfake the first AI video technology?
While not the absolute first academic experiment, Deepfakes were the first application of modern AI (specifically GANs) for video synthesis to gain widespread public attention around 2017. It powerfully showcased the potential—and ethical risks—of the underlying technology.
How has Sora changed AI video generation?
Sora represents a major leap forward in quality, coherence, and length. It was the first widely demonstrated model capable of generating up to a minute of high-definition video that understands complex narrative prompts and basic physics, shifting the perception of AI video from a tool for short clips to one with potential for cinematic storytelling.
Are AI video generators ready to replace professional video production?
Currently, AI video generators are powerful tools for accelerating production, creating marketing content, generating B-roll, and automating repetitive tasks. They significantly reduce costs and time for marketers and creators. While they are not yet replacing high-end, complex filmmaking, they are already disrupting many segments of the traditional video production workflow by offering a viable, cost-effective alternative for many common use cases.
Read More From AI Video Generation
If you found this historical overview helpful, continue exploring our expert, battle-tested guides and comparisons within the AI Video Generation category to find the perfect solution for your needs.
last update : 13/11/2025
